自動化Workerを4個並走させている個人開発者の現実
個人開発の自動化はWorker4個並走しても破綻しない設計が可能です

まず全体像から書きます。個人開発で自動化Workerを複数並走させると、「どこで破綻するか」「運用工数はどれくらい増えるか」が最大の不安要素です。私は GramShift 本体 + W2 note 自動投稿 + ai-pick 記事生成 + バックアップシステムの 4 Worker (+ 各種補助タスク) を毎日並走させていますが、運用工数は Worker 1 個の時とほぼ変わりません。それを成立させているのは「監視一元化」「時間配分の分散」「エラー処理の階層化」の3点で、本文ではこの3点を詳述します。新しいセクションで業界の自動化事例との比較、4 Worker のうち最も価値があった 1 つ、そして増やすときの判断フレームを追加しています。
業界統計を先に置くと、Zapier の "State of Business Automation Report"(出典: zapier.com 系列レポート)では、自動化を導入した中小企業の約 70% が「最大の価値は時間削減ではなく、心理的負荷の削減」と回答しています。個人開発ではこの傾向がさらに強く、Worker 並走の真の価値は「忘れて他のことに集中できる」状態の獲得にあります。
あなたが個人開発で自動化を進めていて、「Workerを増やしすぎると破綻しそう」と不安に感じているなら、私の4個並走の実例が参考になるかもしれません。GramShift本体、W2 note自動投稿、ai-pick記事生成、バックアップシステム、これら4つを毎日並走させて運用しています。実態と設計のコツを共有します。
並走している4つのWorker
私が現在運用している自動化Workerは、ざっくり以下の4カテゴリに分かれます。
- GramShift Desktop: Instagram自動運用、Electron + Playwright、複数アカウント並行
- ParallelIncome W2: note (@ai_fukugyo_ryuji) 自動投稿、Playwright
- ai-pick記事自動生成: 毎日10:00/18:00、Gemini Flash、SFTPデプロイ
- バックアップシステム: 毎日03:00、Google Drive一本化
これら4Worker は別々のWindowsタスクとして登録され、相互に独立して動きます。1つが落ちても他に影響が及ばない疎結合な設計になっています。
リソース競合を避ける時間配分
4Worker を並走させる最大の課題は、リソース競合です。同じ時刻に複数Worker が動くと、CPU・メモリ・ネットワーク帯域を取り合います。私は時間配分を以下のように分散して、競合をゼロにしています。
- 03:00 バックアップ (深夜のみ、他Worker は停止中)
- 06:00-08:00 朝レポート系 (GA4スナップショット、Dashboard集計)
- 10:00 ai-pick記事生成 (朝分)
- 12:00 W2 note投稿
- 18:00 ai-pick記事生成 (夕方分)
各Worker の実行時間が重ならないように、最低 10-15分の間隔を空けています。これでCPU使用率は常に 30% 以下、メモリも空きが十分にある状態を維持できます。
Discord 1チャネル監視で運用負荷を最小化
4Worker を並走させても運用負荷が増えない理由は、Discord 1チャネル #gramshift-alerts に異常通知を集約しているからです。各Worker は処理失敗時に Discord webhook を叩いて通知。私は朝1回 Discord をチェックするだけで、4Worker すべての健康状態を把握できます。
異常がない日は通知ゼロ、何か起きた日は数件の通知が来る、というシンプルなオペレーションです。「常時監視」する必要がなく、「異常時だけ気づく」運用が成立します。
エラー処理の3層設計
4Worker が並走しても破綻しない理由は、エラー処理を3層に分けて設計しているからです。
- 第1層 (Worker内部): try-catch で個別タスクのエラーを捕捉、リトライ機構で一時的失敗を吸収
- 第2層 (タスクスケジューラ): Worker全体が落ちた場合、Windowsタスクの結果コードでエラー検知、Discord 通知
- 第3層 (週次サマリー): 毎週日曜日に1週間の実行履歴を集計、漏れていたエラーを発見
個別Worker の小さなエラーは第1層で吸収、Worker 全体停止は第2層で即時通知、見逃しは第3層で週次確認、という三段構えです。これで「いつの間にか Worker が止まっていた」という事態を防げています。
4Workerでも個人開発で運用できる理由
「Workerを4個も並走させて運用できるのか」と疑問に思う人もいるはずです。実際にやってみると、運用コストは「Worker 1個の時とほぼ変わらない」という感覚です。なぜなら、自動化が成熟すると Worker は「動いていることを忘れる」存在になるからです。
朝起きて Discord を確認、異常がなければ何もしない、というルーチンが確立すれば、4個でも10個でも本質的な負荷は同じです。重要なのは「Worker を増やすこと」ではなく「Worker を確実に動かし続ける運用基盤」を最初に作ることです。Discord 監視、自動アップデート、エラー通知の3点を整えれば、Worker をスケールアウトしても運用工数は線形に増えません。
並走Worker設計の詳細は技術ログ、運用ノウハウは個人開発カテゴリに分けて記録しています。
新セクション: 業界の自動化Worker事例との比較
個人開発の自動化Worker 並走は、業界で見ると「Zapier や Make.com のような SaaS ベース」と「個人ホストの自前 Worker」の2系統に分かれます。それぞれの典型コストと制約を整理します。
| 方式 | 典型コスト/月 | 並走可能数 | 制約 |
|---|---|---|---|
| Zapier (Starter) | 約 $20 | 無制限 (タスク数 750/月制限) | 無料枠で複雑なフローは厳しい、API レート制限 |
| Make.com (Core) | 約 $9 | 無制限 (operations 10,000/月) | 細かい設定が必要、学習コスト中 |
| n8n セルフホスト | VPS代のみ (~$5) | 無制限 | 運用工数あり、VPS 知識必須 |
| 自前 Worker (Windowsタスク + Node.js) | 0円 | 無制限 | 実装工数が高い、ただし完全自由度 |
私が「自前 Worker」を選んだ理由は3つです。第一に、月額 0 円で動かせること(VPS は GramShift 本体と共用、増分コストゼロ)。第二に、Gemini API や Stripe SDK などのコードを直接使えるため、Zapier の中間レイヤーを通すより自由度が圧倒的に高いこと。第三に、Worker 同士の依存関係を疎結合に保ちやすいこと。Zapier/Make では「失敗時の通知をどう繋ぐか」が中央集権設計になりがちですが、自前 Worker では「各 Worker が独立して Discord webhook を叩く」というシンプルなフラット構造が組めます。
ただし、自前 Worker は実装工数が高く、Node.js / Playwright / SQLite / Stripe Webhook 等のスキルを並走で習熟していないと選びにくい選択肢です。業界平均では「最初は Zapier/Make で組んで、スケールしたら自前ホスト or n8n に移行」が王道。私は GramShift 開発の延長で自前 Worker のスキルを既に持っていたため、最初から自前路線でいきました。
新セクション: 4 Worker のうち最も価値があった 1 つ
4 Worker のうち、運用してみて最も価値が大きかったのは バックアップシステム です。一見地味な選択に見えますが、理由は3つあります。
1. 「不可逆な事故」の保険として唯一機能する
GramShift Desktop が落ちても 1 日復旧、ai-pick 記事生成が止まっても 1 日サイト更新がない、W2 note が止まっても 1 日投稿がない、これらは全部「翌日復旧で済む」事故です。一方、ローカルデータが消えると 復旧不可能。バックアップ Worker は「あって当たり前、なかったら廃業」というクラスの保険です。
2. 1 度作れば「触らない」運用に到達できる
GramShift や ai-pick 記事生成は、UI 変更や API レート制限や Meta 検知などで定期的にメンテが必要です。一方、バックアップは「圧縮 → 転送 → 確認」というシンプルなフローで、外部依存が Google Drive だけ。1 度組めばほぼ放置可能で、運用工数が長期的に最も低い Worker です。
3. 心理的安全性の効果が大きい
「いつでも 30 日分前まで戻せる」という安心感は、新しい実装に踏み切る心理ハードルを下げます。バックアップなしの環境だと、本番DB の構造変更や VPS 再起動を躊躇しがちですが、バックアップがあると「最悪戻せる」という前提で攻めた変更が打てます。これは Worker 並走の中で測りにくい価値ですが、個人開発の継続的な改善速度に大きく影響します。
逆に最も「メンテコストが高かった」 Worker は GramShift 本体です。Instagram の DOM 変更や Meta 検知対策で、月に数日はメンテに使うことになります。これは本業 SaaS なので必要コストですが、それ以外の3 Worker と比較すると工数比率が大きく異なります。
新セクション: 自動化Workerを増やすときの判断フレーム
Worker を増やすかどうかは、3軸で評価できます。実際に「これは Worker 化しない」と判断した例も含めて紹介します。
軸 1: Time saved (削減できる手作業時間)
「この作業を Worker 化すると、月何時間の手作業が消えるか」を見積もります。月 1 時間以下なら見送り、月 3 時間以上なら Worker 化検討、月 10 時間以上なら最優先という閾値で運用しています。
軸 2: Risk (Worker が壊れたときの被害)
Worker が壊れたときに「何が困るか」を評価します。被害が大きい (= 復旧不可、顧客影響、収益直撃) ほど、より丁寧な実装 + 監視が必要。被害が小さい (= 1日遅れて済む等) なら、軽い実装でも問題ありません。バックアップ Worker は「壊れたら最終的に廃業リスク」なので最も丁寧に、ai-pick 記事生成は「壊れても1日穴が空くだけ」なので軽量実装にしています。
軸 3: Maintenance (継続的なメンテコスト)
外部依存 (Web スクレイピング、API レート制限) が多い Worker ほどメンテコストが累積します。GramShift 本体は Instagram への依存が強く、メンテ高頻度。バックアップは Google Drive API 依存のみで、メンテほぼゼロ。Worker 化検討時に「3 年運用したら累積何時間メンテにかかるか」を見積もると、軽量に見えた Worker が実は重荷だった、というケースを避けられます。
実例: 「Worker 化しなかった」もの
- SNS 投稿の手動レビュー: Time saved は月 2 時間程度だが、Risk が「ブランド毀損で復旧不可」級。手動の方が安全と判断、Worker 化見送り
- 顧客サポート返信: 月 4-5 時間の手作業だが、Worker 化すると個人運営の信頼度が落ちる。むしろ「個人が直接返信」が差別化になる
- 請求書発行: Stripe が自動でやってくれる範囲で十分、追加 Worker 不要
「Worker を増やすこと」より「Worker 化しない判断」の方が、長期運用では重要です。並走 Worker が無秩序に増えると、運用基盤の複雑度が指数的に上がります。私の 4 Worker は「Worker 化が明確に正解」だったものだけを残した結果です。
まとめ — Worker 数より「並走する設計」が個人開発の生命線
個人開発の自動化 Worker は、4 個でも 10 個でも本質的な運用負荷は同じです。鍵は「監視一元化 (Discord 1 チャネル)」「時間配分の分散」「エラー処理の階層化」と、「Worker 化しない判断」の合計です。Worker 数の自慢ではなく「並走する設計の堅牢さ」が個人開発の継続性を決めます。
関連記事として、Worker の具体実装 (Stripe webhook / Electron / VPS) は技術ログ、運用ノウハウ全体は個人開発カテゴリに蓄積しています。
(本記事は GramShift / saas-diary 開発者 GRAMSHIFT が個人開発で運用している実例ベースです)
実際の Discord 通知 (週次 不労収入ダッシュボード)
並列稼働する Worker 群の運用状況を 1 週間ごとに集計して Discord に送る、自前のダッシュボード通知も例として残します。これは GramShift Monitor (自作) が毎週特定の時刻に各サイトの指標 (GA4 アクセス・記事数・収益化状況) を取得して webhook 経由で #gramshift-alerts に投稿する仕組みです。
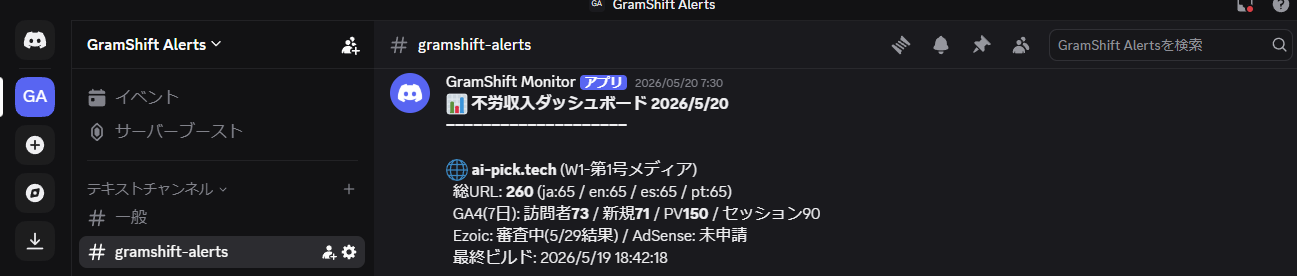
この種の集計通知の運用設計で意識しているのは「ダッシュボードサイトに見に行かなくて済む」点です。GA4 や Search Console を見るのに毎週ブラウザを開くのは面倒なので、必要最小限のメトリクスを Discord に流せば、スマホで通知を見るだけで「今週は順調か / 異常はないか」が判定できます。個人開発スケールの運用効率化として、月 5〜10 分の認知負荷削減が積み上がります。
同カテゴリの記事
個人開発SaaSの周辺トピックとして以下も参考になります。